
【スマホでの数式表示について】
回帰分析とは
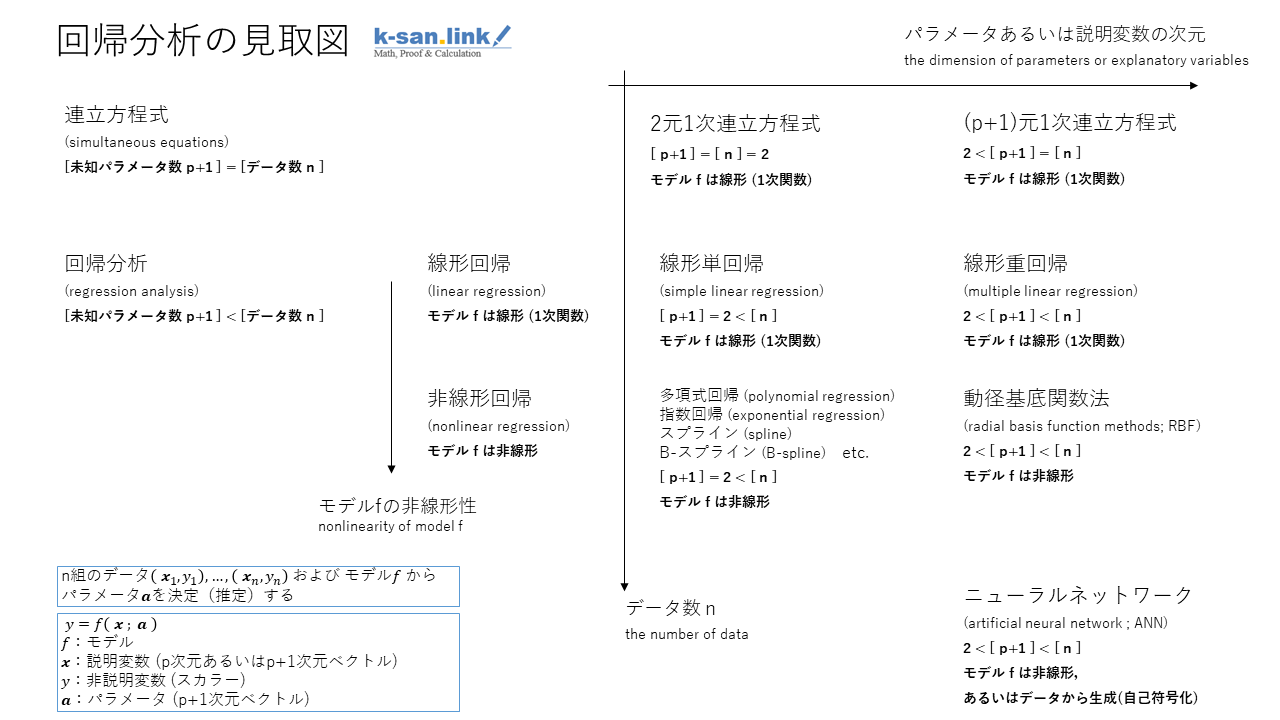
回帰分析(regression analysis)とは,現象のデータとそのモデルとなる関数(族)が与えられたとき,所与のデータを最もよく説明するような関数のパラメータの値を決定(推定)する手法の総称である.
回帰分析は,多変量解析(multivariate analysis)という分野の代表的な手法のひとつであり,多変量解析や,その発展分野である機械学習(machine learning)・人工知能(artificial intelligence)などの諸手法を学ぶ上でも,極めて重要である.
回帰分析の種類
回帰分析は,モデルが線形関数(1次関数)であるか非線形関数(多項式,指数関数など)であるかによって,線形回帰(linear regression)と非線形回帰(nonlinear regression)に大別される.
さらに,線形回帰は,決定すべきパラメータの次元に応じて,線形単回帰(simple linear regression)と線形重回帰(multiple linear regression)に分けられる.
線形回帰は,回帰分析の中で最も単純なものであるが,線形回帰を十分よく理解することによって,回帰分析全般(さらには多変量解析全般)に通じる,重要な基本構造を学ぶことができる.
回帰分析の見取図[PDFダウンロード]
回帰モデルと回帰分析
回帰モデル
自然現象や社会現象などの観測対象に対して,この対象を特徴づける  個の変量(variates) の組
個の変量(variates) の組  と変量
と変量  があり,それらの変量の組
があり,それらの変量の組  に関するデータセット
に関するデータセット
(1) 
が得られているものとする(※注1).また,これらの変量の間に, 個のパラメータの組  を含む
を含む  の関数
の関数  と,何らかの確率分布に従うノイズ
と,何らかの確率分布に従うノイズ  を用いて,
を用いて,
(2) 
のように書かれる関係が存在するものと仮定する.
一般に,現象の観測から得られた統計データが,その現象の背後に存在する数学的構造の下で生成された,と仮定するとき,その数学的構造を現象の 統計モデル(statistical model)という.特に,現象が式(2)によってモデル化(modeling)されるとき,式(2)を 回帰モデル(regression model)という.回帰モデルはよく知られた統計モデルの一種である.
(※注1)確率論において,確率変数は  など大文字で表し,その実現値は
など大文字で表し,その実現値は  など小文字で表す.演繹的体系である確率論では,確率変数が指定されるときには,その確率変数が従う確率分布が同時に指定されている.これに対して,帰納的方法論である統計学では,変量とは「観測項目」のことであり,それを確率変数とみなすべきか否かは自明ではなく,変量の扱われ方は多様である.推計統計学や数理統計学において,変量は,ある未知の確率分布に従う確率変数と同一視され,変量に関する観測値(具体的な数値データ)から,その確率分布(を特定するパラメータ)が推定される.記述統計学や多変量解析における変量は,その変量が従う確率分布をアプリオリに一意に指定できるわけではないという意味で,確率論における確率変数概念とは異なる.
など小文字で表す.演繹的体系である確率論では,確率変数が指定されるときには,その確率変数が従う確率分布が同時に指定されている.これに対して,帰納的方法論である統計学では,変量とは「観測項目」のことであり,それを確率変数とみなすべきか否かは自明ではなく,変量の扱われ方は多様である.推計統計学や数理統計学において,変量は,ある未知の確率分布に従う確率変数と同一視され,変量に関する観測値(具体的な数値データ)から,その確率分布(を特定するパラメータ)が推定される.記述統計学や多変量解析における変量は,その変量が従う確率分布をアプリオリに一意に指定できるわけではないという意味で,確率論における確率変数概念とは異なる.
確率論における「変数」(確率変数とその実現値)および統計学における「変数」(変量とその観測データ)において共通するのは,それらの「変数」概念を記述する際には,3つの記述レベルを用意する必要がある,ということである.
X,Y,…
x,y,…
2.54,3.81,…
回帰分析
現象の観察から回帰モデルを構築(仮定)した段階では,その中に含まれるパラメータ の値は未知(すなわち  は関数族)である.回帰モデル(2)をその現象の予測や制御に用いるためには,すでに得られているデータ(1)を最もよく説明するようなパラメータ の具体的な値を 推定(estimate)する必要がある.
は関数族)である.回帰モデル(2)をその現象の予測や制御に用いるためには,すでに得られているデータ(1)を最もよく説明するようなパラメータ の具体的な値を 推定(estimate)する必要がある.
回帰分析(regression analysis)とは,(1)現象の観測から回帰モデルを構築(仮定)し,(2)回帰モデルのパラメータの推定値(estimates)  を求める,一連の手続きのことであり,また狭義には回帰モデルのパラメータ推定((2)の手続き)を意味する.
を求める,一連の手続きのことであり,また狭義には回帰モデルのパラメータ推定((2)の手続き)を意味する.
線形回帰
回帰モデル(2)における関数  が
が  に関する線形関数であるとき,すなわち
に関する線形関数であるとき,すなわち
(3) 
であるとき,式(3)を線形回帰モデルという.
線形単回帰分析(simple linear regression analysis)とは,ある変量(variate) と別の変量の間に
と別の変量の間に
(4) 
なる関係が存在すると仮定したとき,これらの変量の組 に関するデータセット
に関するデータセット
(5) 
を用いて,パラメータ の推定値(estimate)
の推定値(estimate)  を求めるというものである.
を求めるというものである.
これに対して,説明変数 を多次元の変数
を多次元の変数 に拡張し,これらと被説明変数
に拡張し,これらと被説明変数 との間に線形関係
との間に線形関係
(6) 
があると仮定し,そのパラメータ の値を推定することを,線形重回帰分析(multiple linear regression analysis)という.
の値を推定することを,線形重回帰分析(multiple linear regression analysis)という.



コメントを残す